Higher education has traditionally measured student success through a narrow lens of GPAs, credit hours, and graduation rates. However, modern institutions recognize that a student’s journey is far more complex, encompassing their physical environment, mental well-being, campus engagement, and eventual career readiness. To truly support students from their first day on campus to their transition into the workforce, institutions must look beyond traditional academic metrics and embrace a holistic, campus-wide data strategy.
The Foundation: Enrollment, Aid, and Retention
While expanding our view of the student lifecycle is critical, it must be built on a solid baseline of institutional health. The foundational triad of enrollment strategies, financial aid distribution, and retention rates dictates much of an institution’s operational capability. Connecting these core systems helps uncover which student populations might be financially vulnerable long before they decide to leave.
For a comprehensive breakdown of how bringing these specific financial and demographic metrics together can reveal the true ROI of your institutional investments, check out our recent post on Linking Enrollment, Aid, and Retention. Once that baseline is established, campus leaders can shift their focus to the daily behavioral signals that define the broader student experience.
Proactive Wellness Checks: Safeguarding Through Campus Activity
One of the most vital, yet complex, areas of the student lifecycle is physical and mental well-being. Often, when a student begins to struggle, the first signs aren’t academic—they are behavioral. By thoughtfully leveraging campus infrastructure data, institutions can facilitate proactive wellness checks to support their student body.
This involves monitoring subtle, campus-wide shifts, such as a sudden cessation of dining hall meal swipes or a prolonged absence of residence hall badge-ins. A sudden change in these daily routines can serve as a gentle early-warning signal that a student is isolating themselves or experiencing distress.
The absolute most critical component of this strategy is data privacy and ethical stewardship. This behavioral data must be securely managed—kept strictly private and anonymized within the institution’s architecture. It should only ever be de-anonymized and accessed when absolutely necessary to trigger a secure alert to specialized student life professionals or counselors who can step in to offer targeted support.
Digital Engagement: Navigating the LMS Landscape
A student’s digital footprint provides real-time insights into their academic momentum. Moving beyond simple midterm grades, institutions can analyze Learning Management System (LMS) engagement to gauge academic health. Metrics such as login frequency, time spent reviewing course materials, and participation in discussion boards can identify students who might be quietly falling behind. When these digital engagement metrics are synthesized with advising records, faculty can intervene weeks before a struggling student fails a major assignment, offering tutoring or academic coaching exactly when it will make the most impact.
Extracurricular Connection: The Belonging Metric
Students who feel a sense of belonging on campus are overwhelmingly more likely to succeed. Tracking participation in intramural sports, registered student organizations, and Greek life can help institutions measure this elusive “belonging” metric. If data shows that a specific cohort of first-year students hasn’t engaged with any campus organizations by week six, student affairs teams can launch targeted outreach campaigns, inviting them to specific events or clubs that align with their initial intake interests.
Career Readiness: The Post-Graduation Transition
The final stage of the student success lifecycle isn’t graduation—it’s the successful transition into the professional world. Modern student success tracking should encompass career center engagement, internship placement rates, and alumni networking activities. By analyzing which campus organizations, resume workshops, or early-career interventions yield the highest post-graduation placement rates, institutions can continuously refine their programming to better align with actual workforce outcomes.
Unifying the Lifecycle with The Fusion Platform
The greatest barrier to mapping this complete lifecycle isn’t a lack of data—it’s the presence of departmental silos. Student affairs, academic advising, and the career center often operate on entirely different, disconnected software systems.
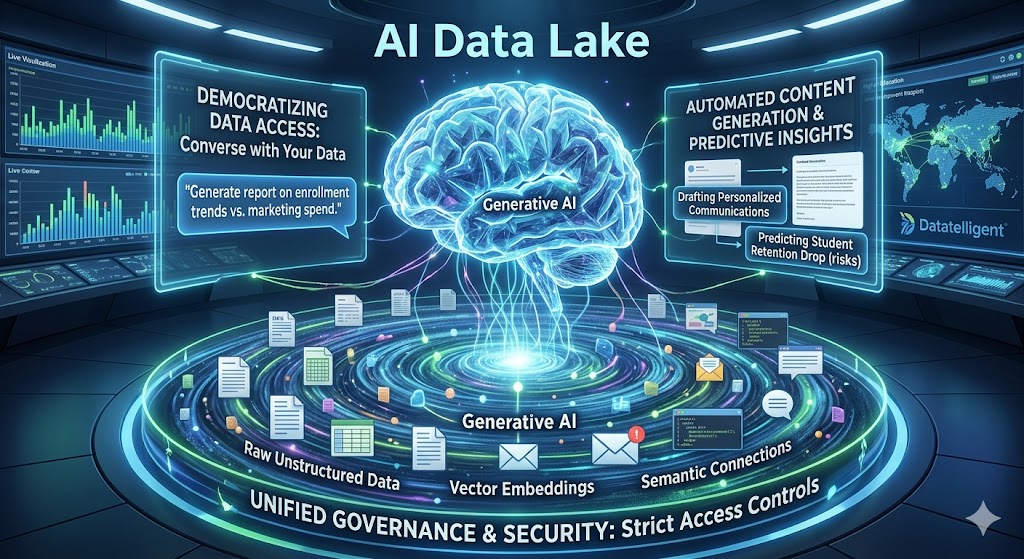
To bridge these gaps, institutions require an advanced institutional data lake capable of handling complex, multi-source inputs. By leveraging The Fusion Platform, universities can securely aggregate SIS records, LMS activity, and campus infrastructure data into one cohesive environment. This centralized approach empowers campus leaders with AI-driven insights, turning fragmented daily interactions into a comprehensive, actionable view of student well-being and success.
Advancing data advocacy in higher education requires ongoing conversation, ethical boundaries, and technological commitment. For more ongoing discussions on how institutional intelligence is transforming the student experience, tune into the Data Stakes podcast, where the conversation continues on how to make campus data work for the students it represents.